Description:
In this quick video, we’ll show how to the use the Data Fill Tool to create a series, a sequence, or a set of random values and store them in the data table. You might use this tool if you want to prepare for data entry or to generate random data.
The dataset you see here was generated using the data fill tool. We’ll now show you how each column was created.
You can load the data fill tool using the menu or by clicking on the shortcut icon in the toolbar.
First, select the column in which you’d like to store the new data. Make sure that the column you choose does not already have data or it will be lost. We’ll use column 4.
Next, choose how to apply the fill. You can generate a single value, a numeric series like 1, 2, 3, etc., a repeating sequence like A, B, C, A, B, C, or random normal or uniform numbers. If you want to generate random numbers from another distribution, use the Data Simulation tool that is also available with NCSS. Let’s first create a numeric series.
Once you’ve chosen what kind of fill to apply, you must specify how the values will be created. Let’s generate values from 1 to 10 with each number repeated 4 times. This should give us 40 values total if we indicate that the fill should terminate when the series limit is reached.
Click “Fill” to generate the data. As you can see, the data have been generated in 40 rows.
Let’s now enter a sequence of text values in column 5 and then add some random normal values in column 6 to match the original example dataset.
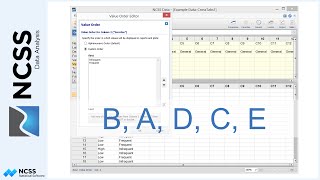
Select column 5 for the fill and choose “Repeating Sequence” as the Fill Type. Enter the sequence, A, B, C, D, with each value repeated a single time and apply the fill until the last row with data. Again, click “Fill” to generate the data.
To generate random normals in column 6, we’ll need to enter a mean and standard deviation for the normal distribution. Enter a mean of 100, a standard deviation of 20, and again fill to the last row with data.
Notice that the newly-generated normal data values are different from the data in column 3, which was also generated with a mean of 100 and standard deviation of 20. This is because the values are random. If you calculate descriptive statistics on both columns of random data, you’ll see that the mean and standard deviation are about the same and match the settings that we used to generate the data.