Description:
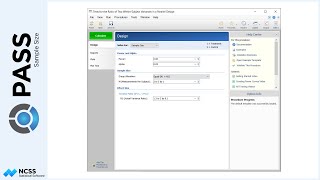
The Randomization Lists tool in PASS can be used to create a randomization list for assigning subjects to treatment groups. The list can further be stratified with up to 2 additional stratification factors.
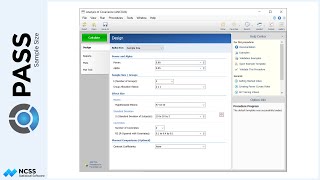
Seven randomization algorithms are available in this procedure. Five of the algorithms are designed to generate balanced random samples throughout the course of an experiment. The other two are less complex but have higher probabilities of imbalance. Many details of these algorithms are covered in the documentation.
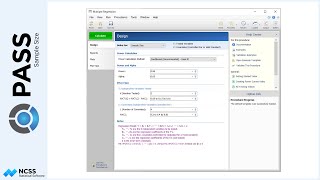
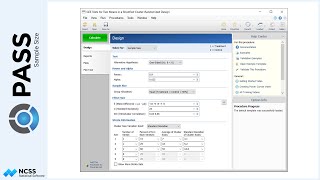
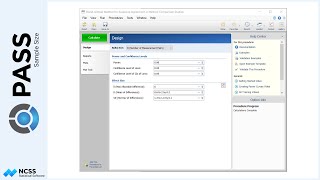
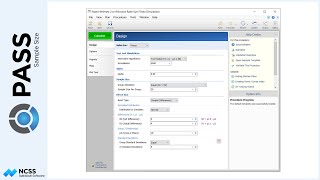
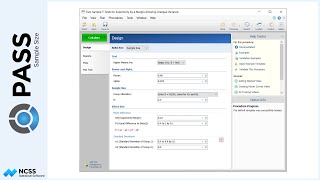
Suppose that a clinical researcher wishes to randomly assign 60 subjects to three treatment groups (Low, Medium, and High) using block randomization with 1-to-1-to-1 allocation, and block sizes of 3 and 6. The list will include sequence numbers, subject ID’s, block identifiers, abbreviated treatment codes, and randomization codes.
For reproducibility, we’ll use a random seed of 60502.
The sequence of assignment of each new patient is given in the first column. The next two columns give a subject identification number and block number. The next two columns identify the randomized treatment assignment for each patient. The final column gives a unique, random, computer-generated code for each subject. This code can be used to blind the study.
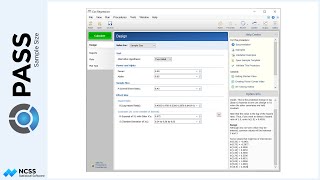
The Cumulative Details report shows the number of accumulated patients with each treatment up to that point in the sequence.
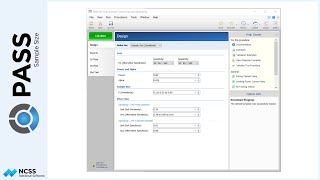
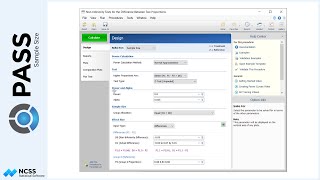
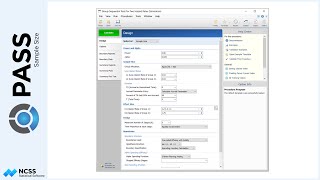
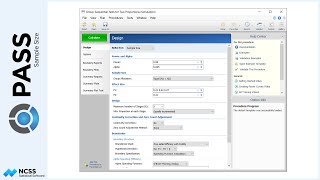
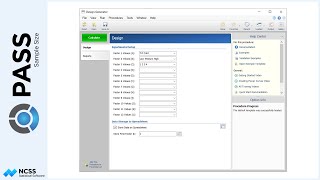
Continuing with this example, suppose the researcher now wants to create a randomization list with twice as many Low treatments as the other two, and at 4 different centers. Each center should have 80 subjects. The researcher wants to randomize with block sizes of 4, 8, and 12 with an equal number of subjects randomized by each block size. The randomization list will also be saved to the spreadsheet.
For reproducibility, a random seed of 102203 will be used.
The randomization list has a length of 320 subjects with 80 each in 4 different centers.
This randomization list was written to the spreadsheet.
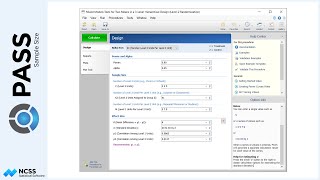
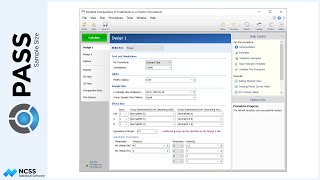
The Randomization List Details report indicates that while it was intended to have an equal number of subjects assigned to each block size, the actual percentages were just a little off due to the discrete nature of the block sizes and total sample size.