Description:
To investigate the calculation of sample sizes in repeated measures designs, we will first go through an example where the key procedure options are highlighted. Then we will take a deeper look at several of the options to get a feel for the flexibility of this procedure.
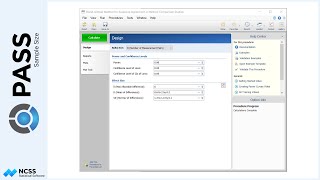
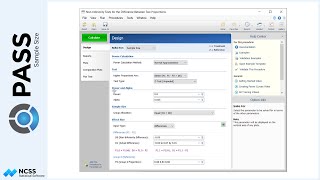
Suppose we are designing a study to compare a new radiation therapy to an existing one. We wish to determine the number of subjects needed to show that the new therapy reduces the size of tumors more efficiently than the current therapy, with 90% power. Individuals receiving either treatment will receive the radiation therapy over the course of four weeks. Each tumor is measured initially and at the end of each week of treatment, resulting in five measurements for each patient. Because the first measurement occurs before a treatment is applied, we will anticipate the analysis comparing the two therapies will be focused on the four measurements following each week of treatment.
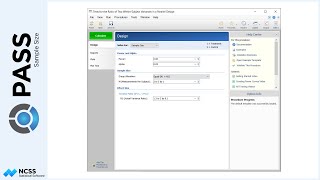
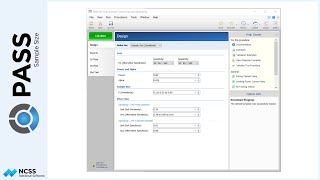
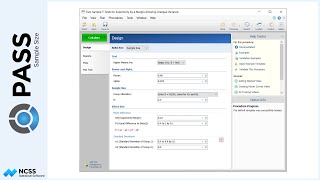
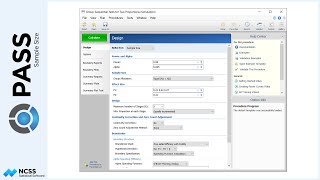
In the model for the analysis of this study, there are three terms: one between term, which is treatment; one within term, which is time or number of weeks; and the interaction of treatment and time. In PASS, the sample size calculation can be based on any of these three terms. Or, we can indicate that we wish to have PASS examine all three terms and report the largest of the three sample sizes. In our case, we would only like to power the study to determine a difference in therapies, so we will focus on the between term, B1.
A variety of univariate and multivariate tests for repeated measures analysis terms can be examined in this procedure. For this example we have chosen F-Test with the Geiser-Greenhouse correction.
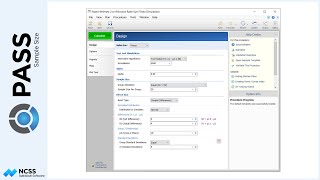
In the study, we would like to determine the sample size to be able to detect a difference in the two radiation therapies if the new therapy is at least 20% better than the current therapy.
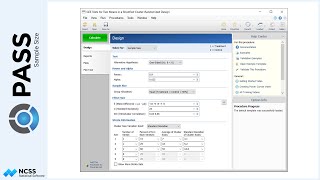
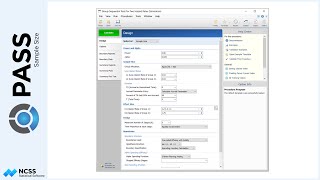
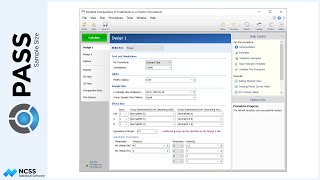
Suppose, in our case, previous studies show the average tumor size before treatment is 212 millimeters. In subsequent weeks the average tumor sizes under the current therapy are 156, 124, 106, and 91 millimeters. One way to specify a 20% reduction in tumor size for the new therapy would be to assume the average tumor size is 20% smaller than the control for each of the last four treatments.
A straightforward way to specify these means is to enter them directly into the spreadsheet.
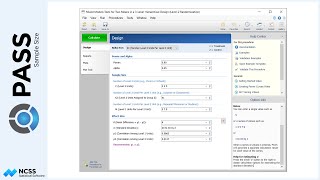
Suppose also that previous studies show the overall standard deviation of tumor sizes at a given time to be 55 millimeters, with an autocorrelation of two measurements on the same subject of 0.16.
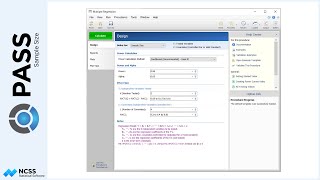
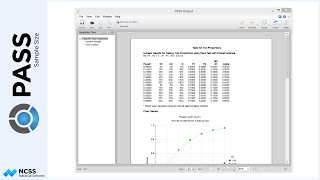
If we calculate the sample size for this scenario, the needed sample size is 43 patients per group, or 86 total patients. Examining the power for each of these terms, we can see that the power requirement is met for the treatment term. We can also see that a study with this number of subjects is well-powered to show a difference between time points. The power is only about 0.1, however, to show a significant interaction. This is to be expected, as there was little interaction of treatment and time in the specified means supplied.
If the new therapy only produces a 10% improvement, the required sample size to detect a difference in treatments increases to 167 per group, or 334.
If the new therapy instead produces a 30% improvement, the required sample size to detect a difference in treatments is only 20 per group, or 40 total.
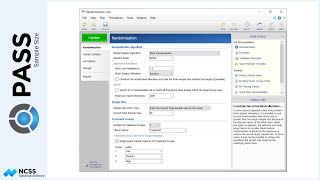
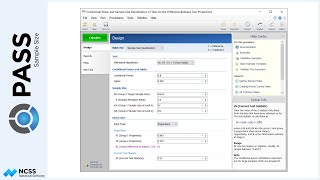
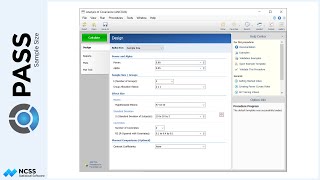
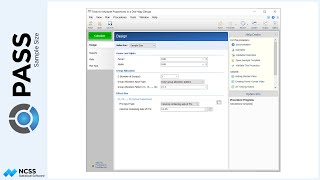
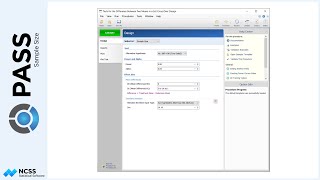
Let’s return the sample size analysis where a 20% reduction is expected. Suppose, now, that we know it is much easier to enlist patients in the study to receive the existing radiation therapy rather than the new therapy. We can ask the software to search for sample sizes with a ratio of 2 to 1 by changing the Group Allocation to ‘Unequal’, and then entering an allocation pattern of 2 and 1. The allocation pattern applies to each of the levels of the between factor.
In this case, the total number of needed patients goes from 86 up to 96, but the number of needed patients in the new therapy group goes from 43 down to 32, while the number needed in the control group goes from 43 up to 64.
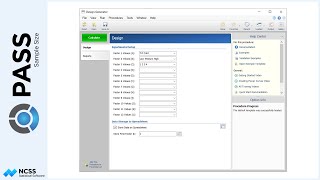
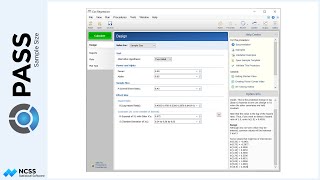
Returning to equal sample sizes per group, suppose that we would like to indicate that the standard deviation decreases as the tumor size decreases. We can specify this by going to the Variances tab and changing the Input Type to ‘Non-Constant’. Based on previous studies, we expect the tumor size standard deviation to be about 68 millimeters initially, and then 57 after week one, 48 after week two, 41 after week three, and 35 after week four. We will still assume the autocorrelation structure is constant at 0.16.
In this case the sample size goes from 86 patients down to 60.
Please note that there are additional autocorrelation structures that could be assumed for calculations.
Or, the entire variance-covariance matrix could be entered directly into a spreadsheet, if desired.
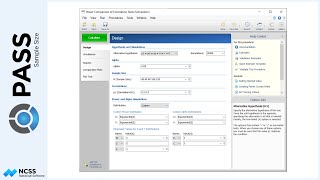
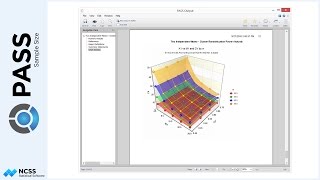
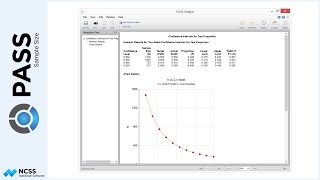
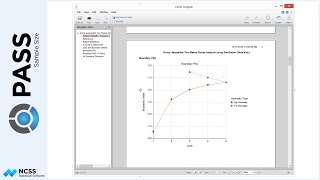
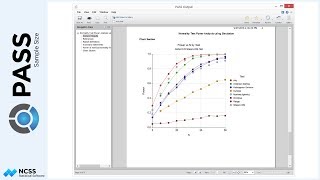
A different approach to planning for this study could be to examine the power for various sample sizes. If we solve for power, and change the group allocation to equal, we can enter a range of sample sizes. The result, in the case, is a power curve for each of the terms in the model.
We can additionally enter a range of effect multipliers. These multipliers can be used to see the consequence of increasing or decreasing the differences in means overall. Because two parameters are varied, the power curves can be viewed on two dimensions or three.
This concludes our discussion of the use of the Repeated Measures Analysis procedure. Additional details and examples of the use of this procedure can be viewed by clicking the help button to access the documentation chapter.