Description:
In this tutorial, we’ll show you how to analyze two-way contingency tables using NCSS. Contingency tables are used to summarize information from 2 categorical variables.
For our first example, we’ll analyze a simple two-by-two table of fictitious data that relates a person’s sugar intake with how often they exercise. Both of the columns that we’ll use in the analysis contain categorical data, so we can use this information in the contingency table without further summarization.
First, load the Contingency Tables procedure from the analysis menu. Set the row variable as Sugar and the column variable as Exercise. Click on the Reports tab to see which reports will be given in the output. In addition to the reports already checked, put a check next to Show Combined Table. Notice that some reports are only given for tables with specific dimensions. Click on the Plots tab and check Show Plots. This set of reports we have selected looks pretty good for our current analysis, so let’s go ahead and run the procedure.
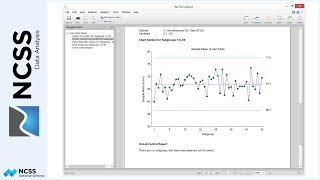
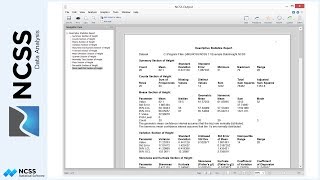
The counts table displays the number of individuals that fall in each category. For example, there are 37 people that have a high level of sugar intake and do not exercise frequently. The combined table indicates that this represents 37% of all respondents. The small p-values in the various tests for independence indicate that there is a significant relationship between the two variables. The bar chart gives a nice graphical representation of this relationship.
In our second example, we’ll use a dataset containing real estate sales data that needs to be summarized before it can be represented in a contingency table. We’ll create a contingency table of City versus Sales Price. On the procedure window set City as the row variable and then check Create Other Column Variables from Numeric Data below Column Variables. In the new input boxes that appear, enter Price as the numeric variable to categorize and select to enter a list of interval upper limits to group the data into categories. Enter one hundred thousand, two hundred thousand, and three hundred thousand as the interval limits. Now, click on the Reports tab and select the desired reports. On the Report Options tab, let’s have NCSS output variable labels and value labels to make the report easier to read. Leave the table formatting options at their default values. Again, click Run to generate the report.
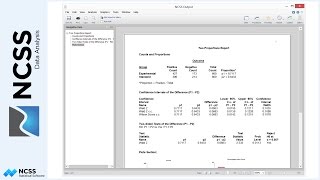
Notice that the table columns are automatically resized to display the data they contain. The row percentages table provides the percentage of homes in each sales price category within each community. The large p-values in chi-square tests indicate that there is no significant relationship between city and sales price.
In our final example, we’ll show you how to modify an unfit dataset to make it possible to generate the kappa statistic. The kappa statistic is used to measure the association or agreement between the measurements from two individuals made on the same individual or item. It can only be calculated for square tables with identical row and column categories. The dataset we’ll use contains responses from 2 raters on 12 different individuals. At a glance the data appear to be just what we need to calculate the kappa statistic. Load the procedure and enter Rater 1 as the row variable and Rater 2 as the column variable. Click on the Reports tab and set the options so that only the individual counts table is calculated along with the Kappa statistics. Click Run to generate the report.
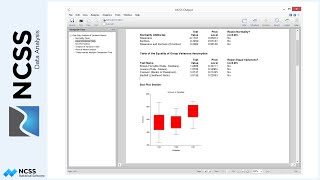
It is instantly apparent from the reports that something is wrong. The kappa statistics were not calculated. The message indicates that something is wrong with the data so that the kappa statistic is not reported. Close inspection of the counts table reveals that although the table is square, the row and column headings do not match. Rater 1 never assigned a 3, while rater 2 never assigned a 2. We need to augment the table with a row and column of zeros to make this table have identical row and column headings. To do this, we need to add a zero to the dataset for the appropriate combination. Go back to the data window and add at the end of the dataset the combination that was never observed. Now we create a new variable called Count and add a count of 1 for all the combinations that were observed and reported and a 0 for that combination that we have just added. Go back to the procedure window and select Count as the Frequency Variable. When we run the report, we find that a row and column of zeros has been added to the table making it suitable for calculation of the kappa statistic. The Weighted Kappa value indicates a moderate-to-high agreement between the two raters.