Description:
In this video tutorial, we’ll cover the basics of comparing two groups using the Two-Sample T-Test procedure in NCSS. To accomplish this, we’ll guide you through a couple of examples that highlight the important points to consider for this analysis.
The two-sample t-test is used to compare means from two groups. The test assumes that
• The data in both groups are continuous, not categorical.
• The samples are independent, such that there is no relationship between the individuals in the two samples
• Both samples are simple random samples from their respective populations
• The data in both groups are normally distributed
and
• The variances in both groups are equal
If the data are not continuous, but are at least ordinal, then the two-sample t-test procedure can still be used to analyze the data, but you may want to consider using one of the nonparametric tests instead of the two-sample t-test to draw your conclusions. An example of this type of data is Likert scale data that often is obtained in surveys, where the respondent is asked to respond on a scale of 1 to 5 to various questions.
If the independence or random sample assumptions are not valid for your data, then the two-sample t-test procedure in NCSS is not the correct procedure for your analysis. For example, if the observations are paired, then it would be appropriate to use the paired t-test procedure instead of the two-sample t-test procedure.
In the sample analyses that follow, we’ll demonstrate how the normality and equal-variance assumptions can be checked and what to do when these are violated.
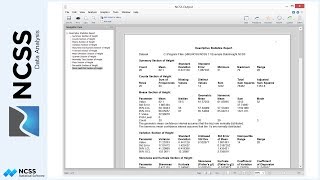
For our first example, we’ll analyze a dataset containing a small random sample of pizza delivery times (in minutes) from 2 companies over 6 months. The data are contained in the example dataset called Pizza. In this example, the delivery times are listed in two columns, side-by-side. The dataset contains 10 observations from company 1 and 8 observations from company 2. There isn’t a lot of data here, but it does represent a typical dataset that’s used in this type of analysis.
The first step in the analysis is to check the data for typos, unexpected missing values, or other errors. When found, any errors should be addressed prior to running the t-test procedure. With small datasets such as this, it’s not too difficult to visually inspect the data. Nothing here looks out of the ordinary.
With the data prepared, let’s load the Two-Sample T-Test procedure for the analysis. First, click Reset to clear any previous changes to the procedure settings. The data in our example are stored in two columns with no grouping variable, so we need to change the Input Type accordingly. Select Pizza 1 as the Group 1 variable and Pizza 2 as the Group 2 variable.
Click on the Reports tab to review to review the output. The reports that are already selected should be sufficient for the common two-sided analysis, so we’ll make no changes here.
Click on the Plots tab. Click on the Histogram format button to modify the histogram. Remember that the plot preview shows only example data, so this does not represent your actual data. Let’s overlay a Density Trace on the histogram along with the normal density. Click OK to save the settings. Now, click on the Probability Plot format button. Click on the checkbox to add confidence limits and click OK.
With the procedure all set up, go ahead and click on the Run button to generate the report.
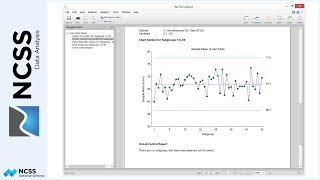
Let’s move first to the Plots Section of the report to graphically investigate the assumption of normality. Looking at the box plot, we can see that Pizza1 has a long left tail and that the median is off-center. Pizza2 looks more evenly-distributed, but is still a little left-skewed. The box plot suggests that there may be a problem with normality here. Remember, however, that these samples are small, and interpretation of box plots for small samples must be flexible.
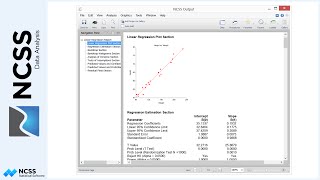
Next take a look at the Normal Probability Plots. All of the points are inside the 95% confidence limits, so this indicates normality for both groups.
The histogram does not usually give an accurate graphical perception of normality for small samples, although the super-imposed density trace helps. With our small sample, there’s not really much you can conclude either way about normality from the histograms and density traces.
At this point of the graphic analysis of the normality assumption, you might reasonably conclude the Pizza2 delivery times are normal while Pizza1 delivery times may not be. However, since these samples are small, we should definitely evaluate the numerical skewness, kurtosis, and omnibus tests for normality. Based on the p-values, all of the normality tests fail to reject the null hypothesis that the distributions are normal. I think we can feel confident from these and the graphical results that there is no clear reason to reject the assumption of normality in each of the groups.
Next, we check the equal variance assumption. If we go back and take a look at the box plots, the spread looks pretty even for both groups. Looking back at the tests for assumptions, neither of the equal-variance tests rejects the null hypothesis of equal variance so we can reasonably conclude that the variances don’t differ substantially.
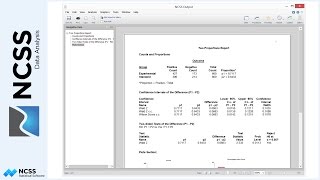
Based on these results, we can conclude that the Equal-Variance T-Test (also known as the Pooled T-Test) is appropriate for the comparison of these groups. Had we concluded that the variances were, in fact, not equal, the Aspin-Welch Unequal-Variance T-Test should have been used.
With a p-value of 0.049 on equal-variance t-test report, we conclude that there is a significant difference in delivery times between the two pizza companies. On average, company 1 takes 3.525 minutes longer than company 2 to deliver pizzas. The 95% confidence interval for the average difference suggests that we are 95% confident that the average difference is between 0.017 and 7.033 minutes.
In our second example, we’ll analyze some real estate sales data to determine if the average home sales price is different between two states, Nevada and Virginia. The data are contained in the example dataset called Resale. All of the sales price data are contained in a single column with the state designations stored in a separate grouping variable. We’ll need to remember this when we specify the procedure input.
A visual inspection of the data is somewhat difficult because of the complexity and size of the dataset. Let’s run it through the Data Screening procedure to look for possible outliers, missing values, and data input errors before we continue to the T-Test procedure. With the Data Screening procedure open, select Price as the variable to screen and click Run to generate the report. The minimum and maximum values look reasonable. Glancing through the report it doesn’t look like there is anything that would indicate an error in the data. It does indicate that there are some outliers.
Now load the Two-Sample T-Test procedure. Don’t click Reset this time because we don’t want to have to set up the plots again. Since we have a single response variable and grouping variable this time, we need to change the Input Type. Select Price as the Response Variable and State as the Group Variable. Click on the Reports tab and add the nonparametric Randomization Test to the output.
On the report options tab, let’s change the settings so that labels are used for both variable names and values in the report.
Click Run to generate the report.
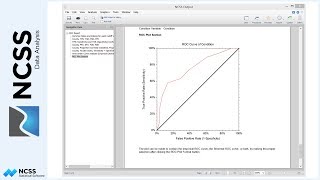
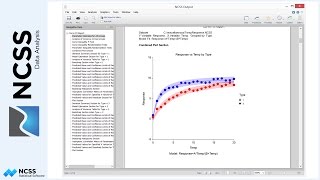
Again, move first to the plots section of the report. Inspection of the box plot, probability plots and histograms indicates that data in both groups are right-skewed and not normal. Unlike the first example, the points in the probability plot are not all within the 95% confidence limits for the normal distribution. The numeric tests for normality confirm this suspicion with normality being rejected by several of the tests. Although the data seem to have equal variances, they are most likely not normally distributed.
Research has shown that the t-test is quite robust in the case where the data are moderately non-normal; however, NCSS provides nonparametric alternatives to the two-sample t-test when this assumption is violated. These include the rank-based Mann-Whitney U Test (also known as the Wilcoxon Rank-Sum Test), the Randomization Test, and the Kolmogorov-Smirnov Test. Of these, the Mann-Whitney U Test is probably the most widely-used. None of the nonparametric tests require the assumption of normality. The Mann-Whitney U Test assumes that the data are at least ordinal in nature and that the distributions are identical, except for the location. Based on these assumptions, the Mann-Whitney U Test seems reasonable for this scenario.
Since there are no ties, we use the Mann-Whitney Test without Correction. With a p-value of 0.4849, we would conclude that there is no difference in median home sales price between the two states. This conclusion is confirmed by all of the other non-parametric tests in the report.
As a final note, it is important to point out here that while the t-test is a test for the means, the Mann-Whitney Test is usually stated and reported in terms of medians, not means. The null and alternative hypotheses relate to the equality and non-equality of the central tendency of the two distributions. The median is a common nonparametric measure of central tendency.