Description:
In this video tutorial, we’ll cover the basics of performing a Multiple Regression analysis in NCSS. To accomplish this, we’ll guide you through an example that will highlight the important points to consider, including how to check assumptions, and how to interpret the results.
Multiple regression is a technique for studying the linear relationship between a dependent variable, Y, and several numeric independent variables, X1, X2, X3, etc. Regression models are often used for two distinct purposes:
• to determine which of the several independent variables are significantly correlated with the dependent variable
and
• to estimate the parameters in a mathematical model of the relationship between Y and the X’s. This model may be used to predict Y for new values of the X’s, or to better understand the relationship.
Each variable entered into the regression model is represented by a single column in the data table. The numeric variables that are used in the model must, at very least, be ordinal if not continuous. When categorical independent variables are entered, the software automatically converts them into one or more ordinal numeric variables before including them in the model.
Our example dataset contains basic information on 150 home sales. In our demonstration, we’ll investigate which of the independent variables Year Built, Bedrooms, Bathrooms, Garage, Fireplace, Quality, Brick, Total Square Feet, Finished Square Feet, and Lot Size are the best predictors of the dependent variable, Sales Price.
Our first task is to scan the data for data-entry errors, unexpected missing values, or other errors. When found, any errors should be addressed prior to running the Multiple Regression procedure because of the distortion that can be caused by one or two data-entry errors. With small datasets, it’s not too difficult to visually inspect the data for typos, outliers, and missing values, but with larger datasets such as this, you may want to run the variables through the Data Screening procedure or plot each X variable versus Y.
Let’s go ahead and run our data through the Data Screening procedure to look for errors. The procedure can be loaded through the Analysis menu.
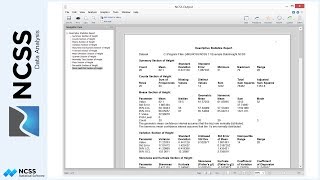
With the Data Screening procedure open, select Price as the variable to screen and click Run to generate the report. Here we’re looking for cases where the minimum or maximum values do not seem correct. For example, had we found that the maximum value for garage were 30 instead of 3, we might consider the possibility that a trailing 0 was added by mistake, since it is highly unlikely that a house actually has 30 garages. For our example, the minimum and maximum values look reasonable for all variables and there are no missing values. The report doesn’t indicate any cause for concern.
Let’s now load the Multiple Regression procedure to proceed with the analysis.
With the procedure loaded, first click Reset to clear any previous changes to the procedure settings. For the Y variable, select Price. For the Numeric X variables, select Year through Lot Size. We don’t have any categorical X’s in this example, so leave that box blank. Also leave the regression model Terms at 1-way so that interaction terms are not added.
Click on the Reports tab to select the reports to include in the output. Click Uncheck All to deselect all of the default reports. Now check the Run Summary report along with Descriptive Statistics, Coefficient T-Tests, Coefficient Confidence Intervals, Normality Tests, R-squared, and Multicollinearity.
Next, click on the Plots tab and again click Uncheck all to deselect the default plots. Check Histogram, Probability Plot, Y versus X and Residuals versus X. Let’s also add 95% confidence intervals to the Probability Plot.
Finally, click the Run button to complete the regression analysis and generate the report.
In the Run Summary Report, verify that the dependent variable is correct and that the number of independent variables is as expected. Also check to make sure that you didn’t inadvertently have a filter running or unexpected rows with missing values. Next, make note of the completion status; in this case the model ran to normal completion. If the program encounters an error during processing, it will be noted here in the summary report. Finally, take a look at the R-Squared value. A value close to 1 indicates that the model fits the data well, while a value closer to zero indicates a poor fit. Remember that the R-squared value will always increase as you add more and more variables to the model, even if they are not significant predictors, so you should be cautious about concluding that a model is adequate for your data based solely on the R-Squared value.
The Descriptive Statistics Report presents summaries similar those we already looked at in the Data Screening procedure report. Again, you’d look here for less-than-expected counts and anomalies in the minimum and maximum values, which would possibly indicate data errors.
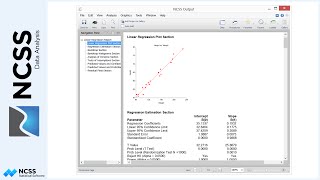
In the Regression Coefficient T-Tests section, record the Probability Level or P-Value for each variable. These probability levels test the significance of each variable with all of the other variables included in the model. In particular, the terms Lot Size, Quality, Total Square Feet, and Year have very small p-values, indicating that they are likely significant predictors of Sales Price. You should consider omitting those variables with a high Probability Level one at a time, starting with the variable with highest P-value, and re-running the multiple regression procedure again and again until you arrive at a model where all of the variables are significant. If you have a lot of variables, we suggest you use the Variable Selection methods in NCSS to find a model with fewer and significant variables.
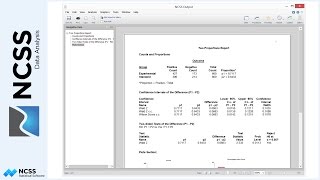
Another assumption of multiple regression is that the residuals are normally distributed. In the Normality Tests report, use the Shapiro Wilk test to check for residual normality. If the Shapiro Wilk null hypothesis of normality is rejected, then the results in this report may be questionable. In this case the null hypothesis of normality is rejected, raising a cause for concern with this model.
The R-Squared Report indicates how the addition or removal of each term affects the overall R-Squared value for the model. You might want to consider removing terms with low R-Squared contributions.
An important assumption of multiple regression is that the predictor variables are independent of each other, so we look at the Multicollinearity Report to check this assumption. This report helps you find independent predictor variables that are highly correlated with other predictor variables in the model. Terms with a variable inflation factor greater than 10 indicate a problem. In this case, there are 2 terms with high variable inflation factor: Finished Square Feet and Total Square Feet. It’s not surprising that these two variables are correlated since both relate to the same type of measurement. You should remove one of these variables before re-running the multiple regression model.
Finally, scan the plots to further check the assumptions. Use the histogram and normal probability plot to investigate the assumption of normality. In this case, the histogram doesn’t look too bad, but the points outside the confidence intervals on the probability plot are consistent with the results from the Shapiro Wilk normality test. It looks like there probably is a problem with the assumption of normality for the residuals of this model.
Next, look at the residual plots for patterns of non-constant variance, outliers, and curvature, which would indicate a non-linear relationship. Overall, these plots look pretty reasonable in this case for these assumptions. In the case where outliers are found, you should consider using the Robust Regression procedure in NCSS which reduces the influence of outliers on the overall results.
Before you save or export your report, you should consider writing comments directly on the report to help you interpret your results in the future. If you’d like to save the report for comparison with a different model, add it to the gallery.
As was mentioned earlier, if we were to take this analysis to completion we might end up running the Multiple Regression procedure several times, transforming data if necessary, until we arrive at a satisfactory model, where all assumptions are met. The analysis might take us into Subset Selection or even into Robust Regression, topics which will be covered in separate tutorials.